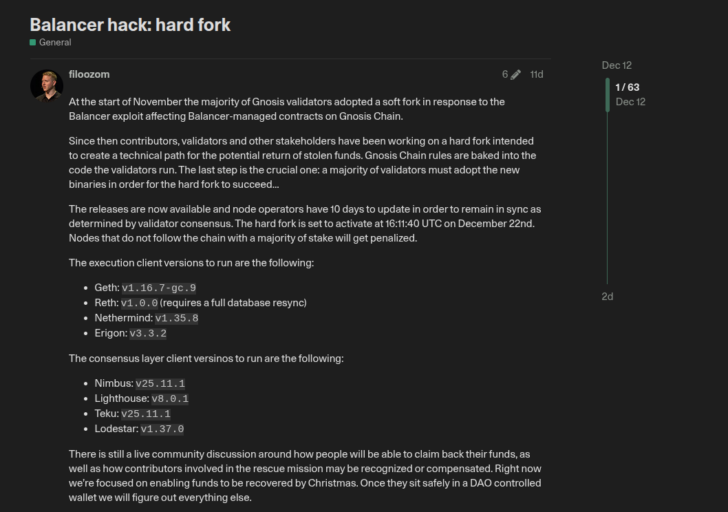
- QVAC Genesis II расширяет открытое обучение искусственного интеллекта до 148 миллиардов токенов в 19 академических областях.
- Набор данных обучает модели объяснять выбор и улучшать рассуждения, выходя за пределы поверхностного понимания .
- Tether Data открыто публикует набор данных, чтобы поддержать исследователей вне закрытых AI-систем.
Tether Data выпустила QVAC Genesis II, расширив свой открытый синтетический образовательный набор данных для искусственного интеллекта до 148 миллиардов токенов в 19 академических областях. Это обновление добавляет 107 миллиардов токенов к предыдущему релизу Genesis I и делает этот набор данных крупнейшим в мире общедоступным синтетическим образовательным ресурсом для предварительного обучения AI.
QVAC, исследовательское подразделение искусственного интеллекта Tether Data, заявило, что целью набора данных является усиление рассуждений, объяснений и принятия решений в AI-моделях, а не только обучение поверхностным паттернам. Релиз выходит на фоне того, что многие продвинутые обучающие наборы данных остаются закрытыми в проприетарных системах, ограничивая доступ для независимых исследователей и академических учреждений.
Масштаб набора данных и академическое покрытие
Расширенный набор данных охватывает 19 академических областей и нацелен на глубину образовательных рассуждений в рамках структурированных задач. QVAC отметила, что увеличение масштаба поддерживает более последовательное обучение моделей, которым требуются объяснительные ответы, а не только вероятностное предсказание текста.
В результате, набор данных фокусируется на ясности и причинно-следственных связях в вопросах и ответах, используемых при предварительном обучении. Набор данных остается открыто доступным для исследователей, университетов и независимых разработчиков, работающих вне закрытых платформ.
QVAC выпустила Genesis II под лицензией Creative Commons Attribution–NonCommercial 4.0, продолжая лицензионный подход, использованный для Genesis I. Организация отметила, что лицензия поддерживает исследовательское использование при сохранении атрибуции и некоммерческих ограничений. Набор данных и связанные с ним модели доступны через Hugging Face, вместе с подробной документацией и инструментами доступа.
Новый метод рассуждения на уровне вариантов ответа
В центре Genesis II находится новый метод генерации данных, называемый Option-Level Reasoning. Этот метод оценивает каждый вариант ответа в вопросе с несколькими вариантами, включая правильные ответы и распространённые заблуждения.
Вместо того чтобы рассматривать правильные ответы как окончательные, подход анализирует, почему каждый вариант успешен или ошибочен. QVAC отметила, что этот процесс укрепляет корректные рассуждения и напрямую устраняет ошибочные предположения в обучающих данных.
Метод основан на фреймворке анализа ошибок, представленном в Genesis I. Вместе обе техники формируют двухэтапный пайплайн, который гарантирует, что каждый сгенерированный элемент вносит образовательную ценность.
Независимые оценки, на которые ссылается QVAC, показывают, что модели, обученные на данных Genesis II, достигают более высокой точности рассуждений и дают более чёткие ответы. В результате, набор данных смещает фокус обучения в сторону структурированного понимания, а не только беглости.
Связано: Tether подала заявку на приобретение футбольного клуба Juventus
Открытые исследования и цели децентрализованного AI
QVAC заявила, что выпуск соответствует её более широкой задаче поддержки локальной и децентрализованной разработки AI. Инициатива направлена на то, чтобы позволить обучение и развёртывание моделей без зависимости от централизованных облачных платформ.
Расширяя открытые основы для обучения, Tether Data стремится устранить структурные барьеры, с которыми сталкиваются небольшие исследовательские группы. «Большинство обучения AI сегодня оптимизировано для беглости, а не для понимания», — сказал Паоло Ардоино, генеральный директор Tether.
«С этим релизом мы выходим за пределы объёма к структуре, рассуждению и ясности», — добавил Ардоино. Он отметил, что открытый доступ предоставляет исследователям инструменты для разработки AI-систем, которые остаются объяснимыми и надёжными.
Техническая статья под названием QVAC Genesis II: Expanding the Largest and Highest-Quality Multi-domain Educational Synthetic Dataset for Pre-training доступна в исследовательском блоге QVAC. QVAC также опубликовала подробный FAQ и сопроводительные материалы на своём официальном сайте.
По мере того как AI-системы проникают в образование, науку и финансовые услуги, включая финтех-приложения, могут ли структурированные наборы данных изменить то, как интеллектуальные системы обучаются и функционируют?